Feature engineering is where most ML trading systems are won or lost — not in model selection. The quality of the input features determines whether a model captures real market structure or memorizes training-period noise.
What You Get
- Feature set specification document: categories, calculation logic, lookback windows, normalization method
- Lookahead bias audit: every feature verified to use only information available at signal time
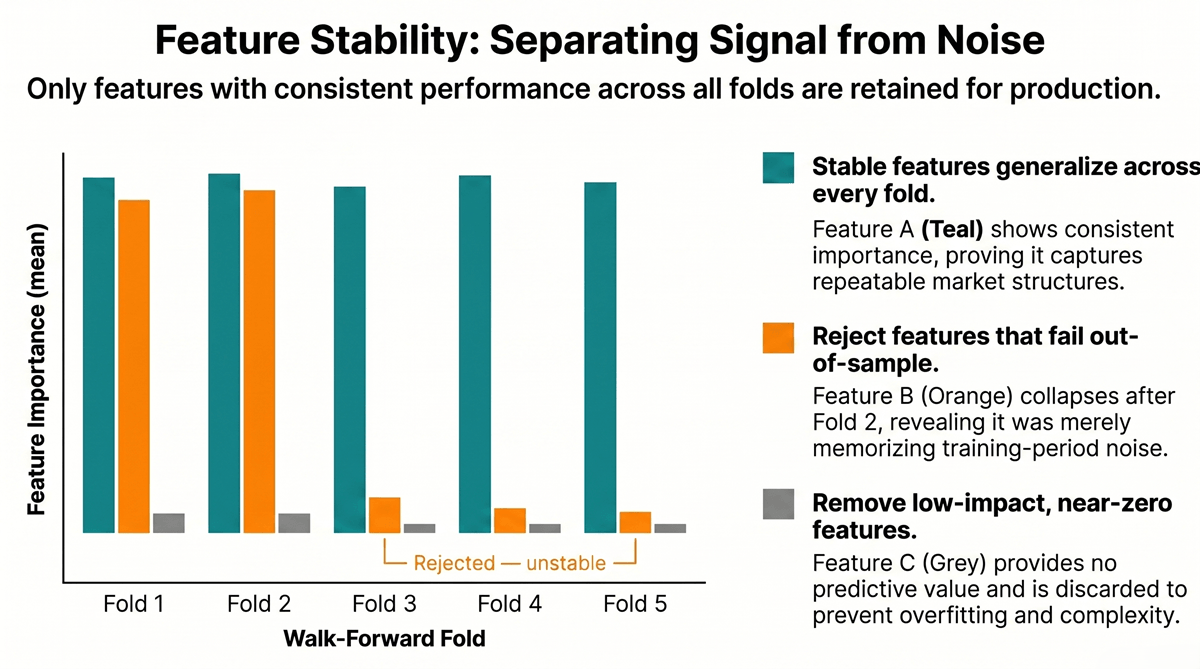
- Walk-forward feature stability report: features tested across multiple time periods to confirm they generalize
- Integration-ready Python code: feature pipeline compatible with the agreed MetaTrader bridge architecture
- Documentation of discarded features and why they were rejected
How It Works
- Strategy review: We examine your trading logic and identify what market conditions the model needs to detect — trend, momentum, regime, volatility state, or session-based patterns.
- Feature design: We construct candidate features across the relevant categories (see table below), calculate each on your historical data, and verify that none introduce future information.
- Stability testing: Each feature is tested across walk-forward folds to confirm it generalizes out of sample. Features that only work in the training period are removed.
- Pipeline handoff: We deliver the Python feature pipeline with clean documentation. If the ML model training is also in scope, the pipeline feeds directly into the training workflow.
Feature Categories We Engineer
| Category | Examples | Typical use case |
|---|---|---|
| Momentum | Rate-of-change at 5/10/20 bars, RSI, distance from moving average | Direction bias, trend strength |
| Volatility | ATR normalized by price, Bollinger bandwidth, rolling realized volatility | Position sizing, regime filtering |
| Market structure | Distance from swing highs/lows, session open behavior, above/below VWAP | Support/resistance context |
| Regime | ADX trend strength, HMM regime labels, correlation with DXY | Context filter (trade only in favorable conditions) |
| Time | Hour of day, day of week, days to NFP/FOMC | Session-aware signal gating — non-optional for FX |
Who This Is For
Good fit:
- You have a trained or partially trained ML model and suspect the features are causing backtest-to-live degradation
- You are starting a new ML trading system and want the feature pipeline built correctly before model training begins
- Your feature set is large and you need an independent audit to identify and remove lookahead-biased inputs
Not the best fit:
- You want a full ML trading system (model + execution) in a single engagement — use the ML Expert Advisor Development service which includes feature engineering as part of the full build
- Your system is rule-based (RSI crosses, moving average conditions) — feature engineering applies to ML models, not traditional EAs; see Expert Advisor Programming instead
What Makes This Different
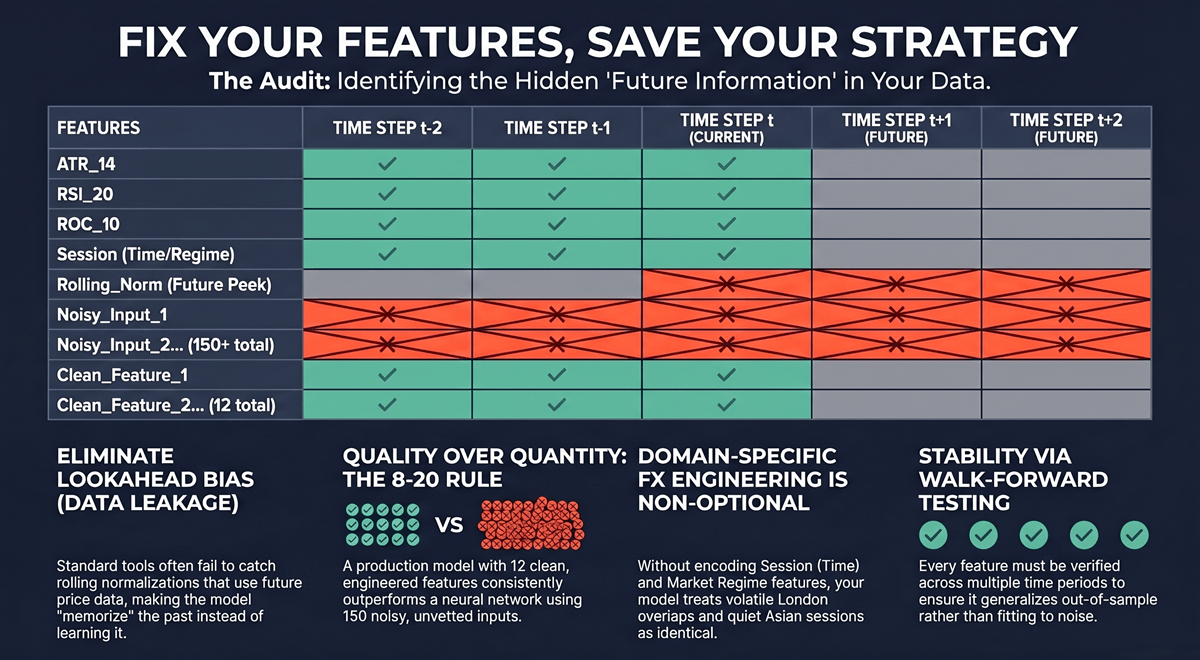
The single most common reason ML trading systems fail in production is data leakage — specifically, features that encode future information during training. This happens in subtle ways that standard ML tooling does not catch automatically.
The most expensive version I’ve seen: a client’s model showed a 0.72 Sharpe ratio in backtest, but normalization was calculated using the full dataset’s mean and standard deviation. The model effectively had access to post-signal price distributions during training. In live trading, the edge was zero. Rebuilding the pipeline from scratch required auditing every feature transformation step-by-step.
Beyond leakage, feature engineering for FX has domain-specific requirements that a data scientist without trading experience will miss. Time features are not optional — a model that doesn’t encode session (London/New York overlap versus Asian session) is treating 3:00 AM EURUSD and 14:00 EURUSD as equivalent inputs. They are not. Regime features matter because a trend-following feature set will generate garbage signals during a mean-reverting regime.
At barmenteros FX, feature engineering audits and pipelines draw on 13+ years of building and debugging algorithmic trading systems. The outcome is a feature set that a model can train on without memorizing the past.
Pricing
Feature engineering scope varies with the number of instruments, timeframes, and feature categories involved. Projects are quoted at a fixed price after a scoping call.
As a reference: ML system builds including feature engineering start at $400 for single-instrument, bar-based systems and range up to $2,500 for multi-instrument, multi-timeframe builds.
Feature engineering audits on existing pipelines (lookahead bias review, stability testing) are quoted separately — typically $150–$400 depending on pipeline complexity.
Request a Quote → — 48-hour response, fixed price agreed before any work begins.
Frequently Asked Questions
What is the most common feature engineering mistake in ML trading?
Lookahead bias — specifically, using a rolling normalization (such as z-score or min-max scaling) calculated on the full dataset rather than a walk-forward window. This means the model saw future price ranges during training and calibrated its internal weights accordingly. The backtest reflects performance that is impossible to reproduce in real time. The fix is to use rolling statistics calculated only from data available at each signal timestamp. Detecting this requires auditing every transformation step in the pipeline, not just the model inputs.
Can I use standard ML feature libraries like ta-lib or pandas-ta?
Yes, but with caution. These libraries produce technically correct indicator values, but they do not enforce lookahead-free computation automatically. When you calculate a 20-period ATR on a full historical series and use the result as a training feature, the ATR value at bar 50 was computed with knowledge of bars 51–2,000. For live use, ATR at bar 50 can only use bars 1–50. The pipeline must replicate this constraint. Wrapping ta-lib functions in a walk-forward framework is standard practice — the library is not the problem, the pipeline architecture is.
How many features should an ML forex model use?
More features is not better. A typical production-ready model for FX direction classification uses 8–20 well-engineered features. Beyond that, the curse of dimensionality and overfitting risk increase faster than predictive value. Feature selection — removing features with low importance or high correlation — is part of the engineering process. A logistic regression model on 12 clean features will consistently outperform a neural network on 150 noisy ones, all else equal.
Do features need to be recalculated when the model is retrained?
Yes. If you are retraining periodically (quarterly, monthly), the feature pipeline must regenerate features from the extended dataset. The normalization windows, regime labels, and any statistics derived from historical data need to be recalculated — because the statistics have changed as new data was added. Pipelines that cache feature values and only append new rows without recalculating the full window are a common source of silent drift in production systems.