Deep reinforcement learning trains a trading agent to optimize performance metrics directly from market data — no manually coded rules, no labeled training examples. The agent learns by acting, receiving rewards, and adjusting its policy through trial and error. It is one of the most technically demanding approaches in algorithmic trading, and one of the most frequently misapplied.
If you are looking to build a DRL trading system or rescue one that is not performing as expected, we offer fixed-price development from specification to live deployment. Get a Free Quote →
What Is Deep Reinforcement Learning in Trading?
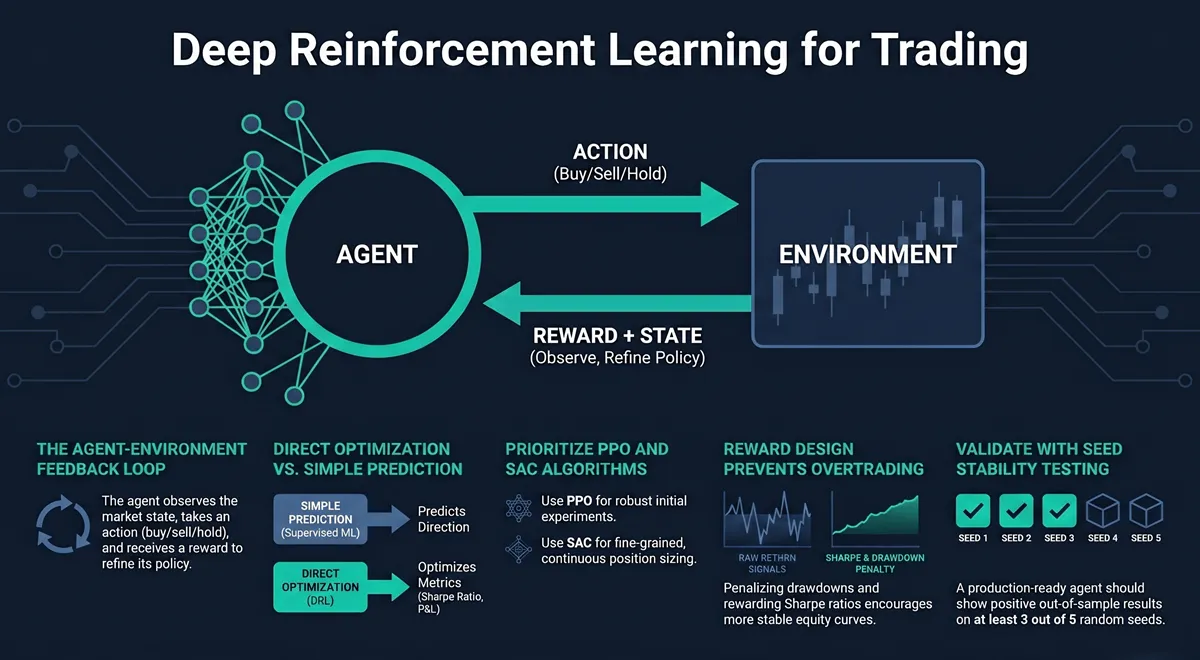
Reinforcement learning frames trading as a sequential decision problem. At each time step, an agent observes the market state, takes an action — buy, sell, hold, or size a position — and receives a reward. The goal is to learn a policy that maximizes cumulative reward over time.
Deep reinforcement learning means the policy is parameterized by a neural network rather than a lookup table. This allows the agent to process the high-dimensional, continuous state spaces that market data produces: price history across multiple timeframes, volatility measures, position state, session encoding — compressed into a dense vector the network can use.
The structural advantage over supervised ML is direct optimization. A supervised model that predicts price direction at 58% accuracy does not directly optimize for P&L — position sizing, execution timing, and risk management are handled as separate downstream components. A DRL agent learns all of these jointly, optimizing the whole system rather than one part of it.
The tradeoff is engineering cost. DRL requires careful environment design, a reward function that reflects what you actually want to optimize, and training stability measures that supervised models do not require. When those three elements are right, a DRL agent can achieve edge that simpler approaches cannot access. When they are wrong, the agent overfits spectacularly and fails immediately in live conditions.
For most FX trading use cases, gradient boosting on engineered features remains more tractable. DRL is the right tool when the action space genuinely requires continuous position sizing, portfolio-level allocation, or joint optimization of signal and execution. See the Machine Learning for Trading overview for a full framework comparison.
DRL Algorithms: DQN, PPO, SAC, and DDPG
Not all DRL algorithms suit trading environments equally. The choice depends on whether the action space is discrete or continuous, and on the tolerance for training instability.
| Algorithm | Action Space | Stability | Best Use Case |
|---|---|---|---|
| DQN | Discrete | Moderate | Buy / Sell / Hold only |
| PPO | Discrete or Continuous | High | First experiments, position sizing |
| SAC | Continuous | High | Fine-grained lot sizing, portfolio weights |
| DDPG / TD3 | Continuous | Low | Mostly replaced by SAC |

DQN (Deep Q-Network) is the entry-level algorithm. It works with discrete action spaces and learns a Q-function — the expected future reward for each action in a given state. The limitation is that discretized position sizing is a crude approximation. If you need “buy 0.07 lots” rather than just “buy,” DQN cannot express that natively.
PPO (Proximal Policy Optimization) handles both discrete and continuous action spaces, which makes it the practical default for initial DRL trading experiments. It is robust to hyperparameter variation and converges reliably enough to diagnose whether the environment design is sound before committing to a more complex algorithm. In live-tested systems I have built, PPO is the starting algorithm on every project.
SAC (Soft Actor-Critic) is the algorithm to use when continuous action space and sample efficiency both matter. SAC maintains an entropy term in its objective — it simultaneously maximizes expected return and the entropy of the policy. This regularization prevents premature convergence to deterministic policies that overfit the training environment. For position sizing in liquid FX markets, SAC typically outperforms PPO in out-of-sample Sharpe ratio given equivalent training time.
DDPG and TD3 are older continuous-action algorithms. TD3 (Twin Delayed Deep Deterministic) improved significantly on DDPG’s instability but has been functionally superseded by SAC for most trading applications. If a research paper recommends DDPG, check the publication date — post-2019 work should be using SAC or TD3.
Learn more: DRL Algorithm Comparison for Trading Systems
Designing the Reward Function
The reward function is where most DRL trading projects fail. The agent optimizes exactly what you specify — not what you intended to specify.
Return-based rewards are the first instinct: reward the agent with bar-by-bar P&L change. The problem is that this conflates high-frequency noise with strategic signal. An agent trained on raw P&L rewards learns to overtrade — it discovers that random activity produces small positive rewards often enough to mask the penalty from large losses. The result is a high trade-frequency strategy with negative Sharpe.
Sharpe ratio rewards address this by penalizing variance. The agent receives a reward proportional to the rolling Sharpe of its returns, encouraging return per unit of risk rather than raw return. This produces agents with lower trade frequency and more defensible equity curves. The implementation requires a rolling window (typically 20–50 steps) and careful normalization — a naively computed Sharpe reward introduces its own training instabilities.
Drawdown-penalized rewards add an explicit drawdown penalty to the return signal:
reward = return_pct − λ × drawdown_fraction − transaction_costWhere λ is a weighting coefficient calibrated per instrument and timeframe. This directly targets maximum drawdown — the metric most relevant for live deployment — rather than optimizing for metrics that get constrained later. Too aggressive a penalty and the agent learns to do nothing (zero-drawdown, zero-return policy). Too weak, and drawdowns in live trading exceed the validated simulation range.

The reward function almost always needs two or three iterations before it produces stable, interpretable behavior. A function that looks correct on paper routinely produces policies that exploit unintended edge cases in the simulation environment. The diagnostic is visual: plot the agent’s position history alongside price over 200+ bars and verify it is taking positions you would recognize as rational.
State Space and Feature Engineering for DRL Agents
The state space defines what the agent observes at each decision step. Standard ML feature engineering principles apply — plus DRL-specific considerations.
Observation window depth: DRL environments typically use 20–50 bar rolling windows as raw input rather than the 100+ bar lookbacks common in supervised models. Longer windows increase network size and training time without proportional benefit. Encode long-range dependencies as derived features (e.g., distance from the 200-day MA as a single scalar) rather than feeding raw price history 200 bars deep.
Position state is mandatory: The current position (flat, long, short) and unrealized P&L must be part of the observation vector. An agent that cannot observe its own position cannot learn rational entry and exit behavior — it cannot distinguish “should I open a long?” from “I am already long — should I add or exit?” This is omitted in a surprising number of published implementations.
Normalization: DRL agents are sensitive to input scale. Price series are non-stationary and cannot be fed raw. Use log returns rather than prices. Normalize features by their rolling mean and standard deviation computed over the training window. Apply the same parameters at inference time — do not refit on test or live data.
Lookahead bias: The same warning from supervised ML feature engineering applies with greater force in DRL. If the reward function or any feature uses future bar data, the agent will learn to exploit that leakage perfectly during training and produce meaningless backtest results. Every feature calculation must be audited for forward-looking dependencies, especially rolling statistics with insufficient lookback fill periods.
Learn more: DRL Environment Design and State Space Engineering
Training Stability and Reproducibility
DRL training is substantially less stable than supervised model training. Two runs of the same algorithm with different random seeds can produce dramatically different policies. This is a property of the algorithm class, not a sign that something is wrong — but it has direct implications for how you validate DRL trading systems.
Seed stability testing: Run every DRL experiment with at least 5 different random seeds and report the distribution of outcomes, not the single best run. If a policy is profitable on only one out of five seeds, it has not learned a stable strategy — it has gotten lucky. A production-ready agent should show positive out-of-sample Sharpe on 3 or more out of 5 seeds.
Training diagnostics: Monitor policy reward, value function loss, and policy entropy during training. A policy reward that oscillates without converging indicates a reward function scaling problem or an excessive learning rate. A value function loss that diverges indicates insufficient network capacity or a replay buffer that is too small. These symptoms can be diagnosed from training logs without domain knowledge.
Parallel environments: Stable Baselines3 and RLlib support training across multiple parallel environments simultaneously. For financial applications, run 4–8 parallel environments initialized with different historical segments of the training data. This improves sample diversity without requiring more total data. It does not cure fundamental reward design problems — it amplifies both good and bad signal.
Overfitting detection: The gap between in-sample policy reward and out-of-sample Sharpe ratio is the primary overfitting diagnostic. A model achieving a 2.5 in-sample Sharpe and 0.3 out-of-sample has overfit the training regime. Reduce model capacity (fewer layers, fewer neurons), add regularization, or simplify the state space. Increasing training data diversity is usually more effective than architectural changes.
DRL vs Supervised ML for Trading
The decision between DRL and supervised ML is a practical engineering question, not an ideological one.
| Factor | Supervised ML | Deep RL |
|---|---|---|
| Optimization target | Prediction accuracy | Direct performance metric (Sharpe, P&L) |
| Data requirements | Moderate — 1,000+ samples viable | High — millions of environment steps |
| Training stability | High | Low — requires seed testing |
| Interpretability | Moderate — feature importance available | Low — policy networks are black boxes |
| Position sizing | Separate layer required | Can optimize jointly with signal |
| Production maintenance | Periodic retraining | Continuous performance monitoring |
For most single-symbol, bar-based FX strategies, supervised gradient boosting with engineered features is more tractable and often more robust than DRL. The engineering overhead of DRL is justified when:
- You want to optimize a portfolio-level metric (Sharpe, Calmar) that supervised models cannot target natively
- The action space requires continuous position sizing or multi-asset allocation
- You have the data volume to support stable training across multiple market regimes
- The team has infrastructure to monitor and retrain a live DRL agent
When these conditions are not present, DRL adds complexity without proportional return.
Learn more: Machine Learning for Trading: Complete Overview
Deploying a DRL Agent on MetaTrader
Training a DRL agent that performs well in simulation is the research problem. Deploying it so it performs consistently in live markets is the engineering problem.
The inference pipeline: At each decision step, the agent requires market features computed from live data in exactly the format used during training, a stateful record of the current position and unrealized P&L, and the policy network loaded into memory. Any mismatch between how features are computed in training versus live creates a distribution shift that degrades performance silently — no errors, just worse results over time.
MetaTrader integration: DRL agents trained in Python deploy via the same bridge architectures used for supervised ML models — named pipe, TCP socket, or file-based communication. See the Machine Learning for Trading page for architecture details. For deploying an existing Python ML model into MT5 without an external runtime dependency, see the Python to MetaTrader Integration service — it covers ONNX-native inference and prediction cross-check methodology. The bar-close latency window is sufficient for 15-minute and hourly agents. Sub-minute agents require the socket or DLL bridge.
Position reconciliation: The agent’s internal position state must stay synchronized with the actual broker state. If the broker rejects an order, partially fills a position, or closes due to a margin call, the agent’s internal position counter diverges from reality. A production DRL EA must reconcile agent state against broker state on every tick — not only at action points.
Live monitoring: Track the distribution of actions the agent takes in live conditions and compare it to the training distribution. An agent that rarely executed “hold” during training but takes “hold” 95% of the time in live conditions has encountered out-of-distribution states. This signals a regime change or an inference pipeline bug — both require investigation before continuing live operation.
Learn more: DRL Trading Agent Deployment: From Python to MetaTrader
Our Expertise in Deep Reinforcement Learning for Trading
I have been building algorithmic trading systems since 2011, with DRL work beginning when Stable Baselines made reproducible RL experiments feasible outside institutional research infrastructure. Since then, DRL projects have ranged from complete system builds — environment design, reward tuning, walk-forward validation, MetaTrader deployment — to rescue work on DRL systems where the backtest-to-live gap became unworkable.
The rescue work is the more instructive category. When a DRL system fails in live conditions, the failure pattern is almost always one of three things: a reward function that looked correct on paper but created unintended incentives, a feature pipeline with subtle lookahead bias, or an inference pipeline that diverges from the training data distribution. None of these are visible in the training metrics. All of them are diagnosable from position history analysis and feature distribution comparison.
Systems I deliver use Python for training and validation (Stable Baselines3, PyTorch, scikit-learn), MQL5 for MetaTrader execution, and bridge architectures chosen for the strategy’s latency requirements. Every delivery includes documented walk-forward validation with seed stability results, not just a single best-run backtest.
Frequently Asked Questions
Which DRL algorithm should I use for a trading system?
Start with PPO. It handles both discrete and continuous action spaces, is robust to hyperparameter variation, and converges reliably enough to determine whether the environment design is sound before investing time in more complex algorithms. Once PPO produces sensible policies, switch to SAC if you need continuous position sizing or higher sample efficiency. Avoid DQN unless you intentionally want a discrete action space (buy/sell/hold only). Avoid DDPG for new projects — it has been functionally superseded by SAC and TD3 for most trading applications.
How much data does a DRL trading agent need?
DRL agents require millions of environment steps to converge. For a 1-hour bar strategy, 5 years of data gives roughly 15,000 bars. Reaching 1M training steps requires looping through the data approximately 65 times — which is standard. The relevant constraint is not total bar count but regime diversity: the training data must include trending markets, ranging markets, high-volatility periods, and low-volatility periods. An agent trained on a single market regime will not generalize. For daily-bar strategies, 10+ years of data is the practical minimum.
Can I deploy a DRL trading agent on MetaTrader?
Yes. The trained policy runs in Python and communicates with a MetaTrader EA via a bridge — named pipe, TCP socket, or file-based communication depending on the strategy’s latency requirements. The EA sends the current market features and position state to the Python process, receives the action signal, and executes it using standard order management logic. Bar-based strategies (15-minute and above) work well with file-based or named-pipe communication. The critical requirement is that the feature engineering in the live EA exactly replicates the feature engineering used during training. Any divergence creates distribution shift.
What is reward shaping in DRL trading and why does it matter?
Reward shaping is modifying the reward function to guide the agent toward desired behavior more effectively. Raw P&L as a reward signal is too noisy for the agent to learn from efficiently — small losses and random gains are indistinguishable from signal. Reward shaping adds structure: penalizing drawdown, penalizing excessive trade frequency, incorporating transaction costs, or rewarding Sharpe ratio rather than raw return. When done carefully, shaping accelerates learning and produces policies that trade more rationally. When done carelessly, it creates unintended shortcuts — the agent learns to maximize the shaped reward rather than the underlying trading objective. Always verify that improvements in shaped reward correlate with improvements in out-of-sample Sharpe.
When does a DRL trading system outperform a traditional expert advisor?
DRL outperforms a traditional EA when the strategy requires joint optimization across signal generation, position sizing, and timing — components that a rule-based EA handles as separate, manually tuned modules. The clearest use cases are: position sizing that responds continuously to market volatility rather than applying a fixed formula; portfolio allocation across multiple instruments where correlations shift over time; and execution strategies that adapt to liquidity conditions. For strategies with stable, expressible logic — a momentum signal with fixed risk management on a single instrument — a rule-based EA is typically more robust and significantly easier to maintain.
Next Steps
If you have a trading strategy you want to implement with deep reinforcement learning, or a DRL system that is not performing as expected in live conditions, get in touch for a fixed-price scoping assessment.
Every project starts with a written specification covering the strategy, action space design, reward function candidates, and platform integration. The fixed price is agreed before development begins.
Get a Free Quote — 48-hour response, no obligation.